Saya harus belajar statistika lagi…
TL;DR
Mau ngasih tau langkah-langkah pengujian Chi-Square pakai R untuk analisis data curah hujan.
Maksud dan Tujuan
Kali ini saya akan melakukan pengujian Chi-Square atau Khi-Kuadrat (kata Wikipedia) pada data curah hujan Samarinda. Bacanya khay bukan chiy!
Pengujian ini termasuk analisis uji kecocokan sebaran, yaitu goodness of fit test (oppo iku?). Dipakai untuk menguji kecocokan distribusi frekuensi sampel data terhadap fungsi distribusi peluang yang diperkirakan dapat menggambarkan atau mewakili distribusi frekuensi tersebut (rumitnya bahasa copas).
Gampangnya gimana? Kenapa perlu ada uji Chi-Kuadrat \((\chi^2)\)?
Maksud dari pengujian ini adalah untuk menentukan persamaan distribusi yang akan dipilih nanti, apakah bisa mewakili distribusi statistik sampel data yang dianalisis atau tidak.
Selain dengan metode ini, pengujian lain yang juga sering dipakai untuk analisis kecocokan distribusi curah hujan adalah metode pengujian Kolmogorov-Smirnov. Hwaadaaw~!
Nanti kita belajar yang itu juga, insyaAllah…
Syarat
Analisis bisa diterima kalau nilai Chi-Kuadrat yang kita hitung kurang dari Chi-Kuadrat Kritis \((\chi_{h}^2 < \chi_{cr}^2)\). Nilai kritis itu diperoleh dari tabel, atau melalui fungsi yang disediakan oleh R. Hhm… menarik.
Sumber Data
Saya dapat data hujan ini dari seorang teman yang tinggal di Samarinda. Dia ambil bidang peminatan studi yang sama dengan saya. Jadi, dia juga ngolah data hujan gitu, seperti saya. Dan dia dapat data ini dari mana? Pasti dari instansi penyedia data meteorologi setempat (saya menerka).
Data adalah curah hujan maksimum tahunan.
Data ini sudah saya rapikan dan disimpan dalam format csv agar teman-teman bisa langsung ikut mempraktikan apa yang saya tulis di sini.
Silakan unduh melalui tautan ini (klik kanan lalu save as). Atau tidak usah juga tidak apa. Nanti kita bisa akses langsung saja dari url di RStudio kesayangan Anda. Seperti yang akan kita lakukan berikut.
Persiapan Data
Lakukan impor data dari repositori github (pakai koneksi internet).
url <- "https://raw.githubusercontent.com/akherlan/blog/master/static/data/hujan-samarinda.csv"
data <- read.csv(url)
data## tahun data
## 1 1999 117.1
## 2 2000 83.8
## 3 2001 101.6
## 4 2002 66.3
## 5 2003 87.7
## 6 2004 118.2
## 7 2005 108.0
## 8 2006 132.1
## 9 2007 94.4
## 10 2008 73.0
## 11 2009 60.2
## 12 2010 86.5
## 13 2011 105.5
## 14 2012 98.9
## 15 2013 96.0
## 16 2014 102.5
## 17 2015 78.8
## 18 2016 120.1
## 19 2017 102.3summary(data)## tahun data
## Min. :1999 Min. : 60.20
## 1st Qu.:2004 1st Qu.: 85.15
## Median :2008 Median : 98.90
## Mean :2008 Mean : 96.47
## 3rd Qu.:2012 3rd Qu.:106.75
## Max. :2017 Max. :132.10Jika tadi sudah mengunduh datanya terlebih dulu, maka bisa mengganti nilai yang didefinisikan ke url dengan lokasi penyimpanan berkas .csv-nya.
Pengolahan Data
Pertama, kita akan membagi data menjadi kelompok-kelompok tertentu (distribusi frekuensi). Tapi sebelumnya, ada beberapa parameter yang harus ditentukan dulu seperti di bawah.
1. Jumlah kelas data
Katakanlah kita ingin membuat kelompok-kelompok tertentu untuk mencacah data kita. Jumlahnya (\(G\)) bisa kita hitung dengan persamaan ini:
\(G = 1 + 3.322 \times log(n)\)
dengan \(n\) merupakan jumlah data yang kita punya.
# nilai G yang dibulatkan ke atas
g <- ceiling(1 + 3.322 * log10(nrow(data)))
g## [1] 62. Interval kelas
Interval antar kelompok (\(\Delta X\)) bisa kita tentukan dengan cara berikut:
\(\Delta X = \frac {X_{max} - X_{min}}{G - 1}\)
Dimana, \(X_{max}\) merupakan nilai data paling besar dan \(X_{min}\) merupakan nilai data paling kecil.
# interval data
int <- (max(data$data) - min(data$data)) / (g-1)
int## [1] 14.383. Batas-batas kelas
\(X_{awal} = X_{min} - 0.5 \Delta X\)
\(X_{akhir} = X_{max} + 0.5 \Delta X\)
# batas awal kelas
awal <- min(data$data) - 0.5*int
awal## [1] 53.01# batas akhir kelas
akhir <- max(data$data) + 0.5*int
akhir## [1] 139.29Sampai di sini, kita sudah tahu bahwa nanti kita buat data jadi enam kelompok. Batas awal 53.01 dan batas akhir 139.29 dengan interval 14.38.
Setelah ditentukan batas-batas dan interval data, sekarang kita bisa mendistribusikan data ke dalam masing-masing kelompoknya, yang ada enam itu.
Misal, kalau ada rentang data 0-10, kita buat jadi 5 kelompok dengan interval 2. Maka nilai 9 akan kita masukkan ke kelompok data 8-10, bukan kelompok data 4-6, dan dihitung 1. Kalau ada nilai 10. Kita masukkan lagi ke kelompok 8-10. Jadi sekarang ada 2 frekuensinya. Begitu juga dengan nilai lain.
Caranya…
# buat kelompok-kelompoknya
kelompok <- seq(awal, akhir, by=int)
# menghitung frekuensi (banyaknya data) tiap kelompok
masuk.kelas <- cut(data$data, kelompok, right = FALSE)
freq <- table(masuk.kelas)
dist.freq <- cbind(freq)
dist.freq## freq
## [53,67.4) 2
## [67.4,81.8) 2
## [81.8,96.2) 5
## [96.2,111) 6
## [111,125) 3
## [125,139) 1Sekarang, kita sudah memperoleh frekuensi dari masing-masing kelompok data.
Menghitung Chi-Kuadrat
Aslinya, rumus untuk menghitung Chi-Kuadrat adalah seperti ini:
\(\chi_{h}^2 = \sum\limits_{i=1}^G \frac{{(O_i - E_i)}^2}{E_i}\)
Tapi di R, ada fungsinya, tinggal pakai chisq.test(datakamu). Untuk kasus data curah hujan yang kita punya, jadi begini:
chisq <- chisq.test(dist.freq)
chisq##
## Chi-squared test for given probabilities
##
## data: dist.freq
## X-squared = 5.9474, df = 5, p-value = 0.3114Ketika membandingkan \(\chi_{h}^2\) dengan \(\chi_{cr}^2\) sesungguhnya saya mengalami kebingungan. Ada dua versi…
Versi pertama1
Dengan derajat kebebasan (degree of freedom = df) yang diperoleh dari \(G-1\), sehingga menghasilkan \(df = 5\). Nilai ini sesuai dengan hasil perhitungan di R menggunakan fungsi chisq.test().
Versi kedua2
Dengan derajat kebebasan yang dihitung berdasarkan dua kondisi, yaitu:
- untuk distribusi normal dan binomial \((P = 2)\)
- untuk distribusi gumbel dan poisson \((P = 1)\)
dihitung dengan cara \(G-(P+1)\) sehingga menghasilkan \(df = 3\) (untuk distribusi normal).
Entahlah, harus belajar lagi. Tapi untuk sementara mari kita gunakan yang versi kedua untuk kasus kali ini. Nanti kalau sudah ketemu jawaban paling tepat akan saya perbarui artikel ini.3
Kita tidak menggunakan nilai p (p-value) yang dihasilkan dari perhitungan Chi-Square melalui fungsi chisq.test() karena \(df = 5\) sedangkan yang kita perlukan adalah \(df = 3\). Sehingga kita akan mencari nilai p pada selang kepercayaan 0.05 (persentil ke-95).
Untuk memperoleh nilai Chi-Square kritis \((\chi_{cr}^2)\) bisa dengan fungsi berikut:
qchisq(0.95, df = 3)## [1] 7.814728Kesimpulan
Data hujan bisa diterima karena nilai Chi-Kuadrat hitung \(\chi_{h}^2 = 5.947\) kurang dari nilai kritis \(\chi_{cr}^2 = 7.815\) (selang kepercayaan 0.05 untuk distribusi normal).
Yah, begitu. Gampang bukan?
Bonus!
Kalau teman-teman gak mau pakai R, mau pakai Excel saja! Mari bandingkan hasilnya.
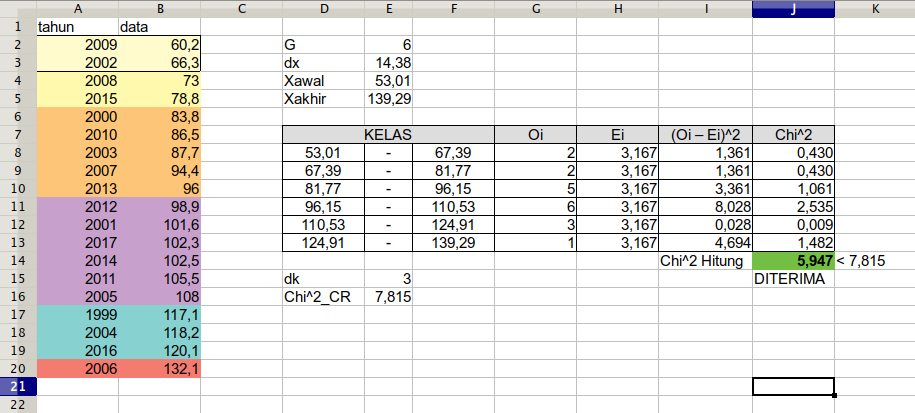
Menghitung uji Chi-Square dalam worksheet
Demikian saya sampaikan. Sekian. Terima kasih.
Referensi
- Analisa Frekuensi dan Probabilitas Curah Hujan | unduh pdf lewat telegram (di dalamnya ada tabel \(\chi^2\) kritis)
- Distribusi Frekuensi Data Kuantitatif di web R-Tutor.com
- The Goodness Fit di web R-Tutor.com
- Distribusi Chi-Kuadrat di web R-Tutor.com
Dari pernyataan dalam halaman web Sciencing.com bagian Calculating, juga dalam Statistikian pada bagian Chi Square Hitung VS Chi Square Tabel.↩
Norma Puspita, S.T., M.T., pada halaman 13 tutorial berikut (format pdf).↩
Mohon bagi pembaca yang tahu jawabannya untuk menghubungi saya lewat telegram. Terima kasih~↩