Pusing nggak, sih, nyari data? Huuft…
Objective
Tutorial ini merupakan catatan pengingat bagi saya. Kan, syukur kalau bisa dibagi ke teman-teman semua. Tujuan tutorialnya adalah untuk membuat visualisasi “kekosongan” data hujan yang saya miliki. Atau dengan kata lain untuk mengetahui berapa persen sih kelengkapannya?
Harapannya: agar tahu mana yang masih harus dilegkapi. Juga bisa memilih data hujan mana, serta data hujan kapan yang bisa saya gunakan untuk tahap analisis berikutnya.
Preparation
Yang kita butuhkan untuk melakukan ini semua tentu saja data hujan. Saya menyimpannya dalam format .Rda. Sebenarnya juga bisa dari .csv atau .xls, tapi kalau dalam format data R tentu lebih rapi. Jadi saya pakai itu. Data hujan yang saya gunakan ini juga sudah bisa teman-teman akses dari tadi sebenarnya. Resolusi datanya hujan harian.
Selain data, kita juga butuh beberapa paket library untuk manipulasi. Makna manipulasi di sini bukan “memalsukan”, tetapi “ngotak-ngatik”.
# library yang dibutuhkan
library(dplyr) # manipulasi data
library(lubridate) # manipulasi tanggal
library(ggplot2) # plot grafik# memuat data
load(file = "~/R/repo/hujan/data/prc/Raingauge/Precip.Rda") # sesuaikan lokasi file
Precip <- Precip[!is.na(Precip$tgl),] # menghilangkan hari yang kosong (aneh, ya?)
Precip$NamaStasiun <- as.factor(Precip$NamaStasiun) # kategorisasi nama stasiun
summary(Precip)## NamaStasiun LONx LATy tgl
## PLTA Kracak: 5114 Min. :106.5 Min. :-6.728 Min. :1996-01-01
## Empang : 3651 1st Qu.:106.7 1st Qu.:-6.617 1st Qu.:2004-01-06
## Dramaga : 3593 Median :106.8 Median :-6.601 Median :2006-04-18
## Katulampa : 3564 Mean :106.8 Mean :-6.551 Mean :2006-01-17
## Depok : 3561 3rd Qu.:106.8 3rd Qu.:-6.446 3rd Qu.:2008-06-02
## Pasir Jaya : 2882 Max. :107.1 Max. :-6.405 Max. :2014-12-31
## (Other) :25099 NA's :16094 NA's :16094
## prc
## Min. : 0.000
## 1st Qu.: 0.000
## Median : 0.000
## Mean : 8.494
## 3rd Qu.: 10.000
## Max. :290.000
## Data ini sudah saya rapikan sebelumnya. Agar teman-teman bisa mengakses data ini dari RStudio di komputer masing-masing, silakan sesuaikan nilai "~/R/repo/hujan/data/precip.Rda" dengan direktori yang tepat sesuai lokasi teman-teman menyimpannya.
Simpan dalam hati? Oh, jangan.
Kembali ke laptop!
Kalau diperhatikan dari hasil summary data, kolom tanggal (tgl) dan kolom curah hujan (prc) sudah tidak ada data kosong (NA) seperti pada (LONx, LATy). Tetapi, sebenarnya ada beberapa tanggal yang data hujannya memang kosong. Hanya saja saya hilangkan.
Maka berikutnya, kita akan menghitung jumlah stasiun yang punya rekaman data pada hari X. Check it out!
Counting Data
p.mod <-
Precip %>%
group_by(tgl) %>%
summarise(count = sum(as.numeric(ifelse(!is.na(prc), yes = 1, no = 0)))) %>%
mutate(persen = (count / nlevels(Precip$NamaStasiun))*100)Baris kode di atas akan membuat tabel baru bernama p.mod, yang merupakan ringkasan dari tabel Precip dengan nilai-nilai yang kita butuhkan untuk membuat visualisasi.
- Bagian
count = ...bertujuan untuk membuat kolom baru yang berisi hasil hitungan jumlah data. Jika pada hari X stasiun hujan Q memiliki rekaman data, maka dihitung satu. Termasuk data nol (0 bukan NA). - Bagian
persen = ...adalah untuk membuat kolom baru yang berisi perhitungan persentase data hujan harian yang tersedia dari ke-19 stasiun hujan yang digunakan datanya. Jumlah stasiun yang punya data harian (nilai dalam masing-masing cell pada kolom count) dibagi dengan jumlah stasiun (nlevels(Precip$NamaStasiun)) kemudian dikali 100 persen.
Kalau kita lihat struktur tabel p.mod itu seperti berikut.
str(p.mod) # struktur data## tibble [6,881 × 3] (S3: tbl_df/tbl/data.frame)
## $ tgl : Date[1:6881], format: "1996-01-01" "1996-01-02" ...
## $ count : num [1:6881] 1 1 1 1 1 1 1 1 1 1 ...
## $ persen: num [1:6881] 5.26 5.26 5.26 5.26 5.26 ...Kalau dilihat dalam bentuk tabel, seperti di bawah ini.
head(p.mod) # menampilkan 6 rekaman data teratas## # A tibble: 6 x 3
## tgl count persen
## <date> <dbl> <dbl>
## 1 1996-01-01 1 5.26
## 2 1996-01-02 1 5.26
## 3 1996-01-03 1 5.26
## 4 1996-01-04 1 5.26
## 5 1996-01-05 1 5.26
## 6 1996-01-06 1 5.26Plotting
Tiba saatnya untuk plotting grafik. Waktu yang ditunggu-tunggu. Berikut baris data yang digunakan.
p.mod %>%
mutate(bulan = month(tgl, label = TRUE, abbr = TRUE),
tahun = year(tgl),
hari = wday(tgl,label=TRUE),
pekan = ceiling(day(tgl)/7)) %>%
group_by(bulan, tahun, hari, pekan) %>%
ggplot() + aes( hari, pekan, fill = persen) +
geom_tile(colour = "white") +
facet_grid(tahun~bulan) +
scale_fill_gradient2(low="blue", mid="yellow", high="red",
na.value = "grey70", midpoint=50) +
theme(axis.title=element_blank(),
axis.text=element_blank(),
axis.ticks=element_blank(),
strip.text=element_text(angle=0),
strip.text.y=element_text(angle=0),
panel.spacing = unit(0, "lines"))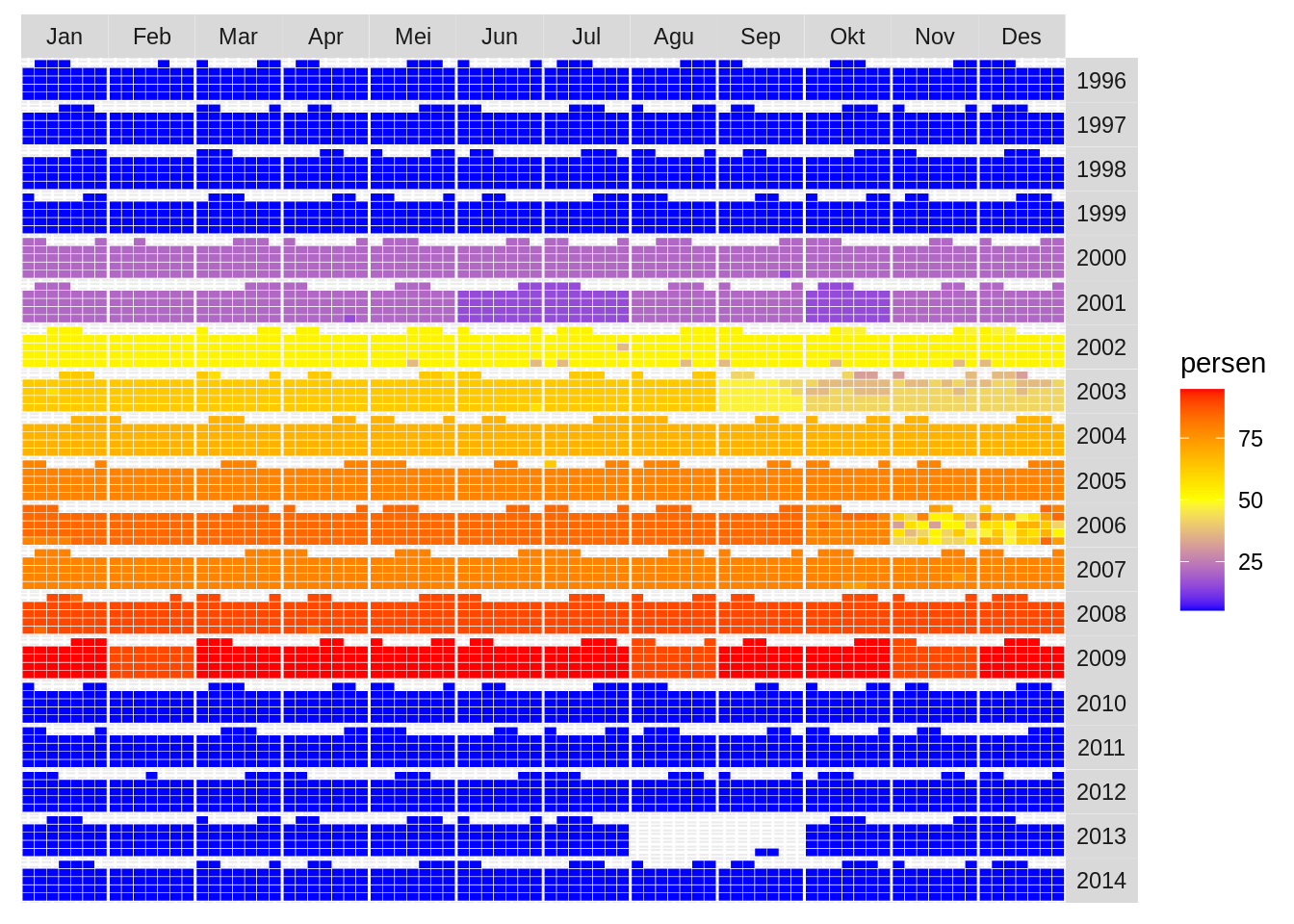
Taraaaaa, jadi.
Hhmmm… Data paling lengkap sepertinya pada 2009. Sepakat? Atau kita eliminasi saja stasiun hujannya. Hahaha… Pada 2013 terjadi ke-ompong-an. Kita pakai 2004-2009 saja, bagaimana?
Terima kasih. Semoga bermanfaat.
Layangkan komentar teman-teman dengan cara mention di Twitter, dm Instagram, atau pesan Telegram.
Reference
- Manuel Gimond’s note here